Sidi is a Chinese reading tool for serious Chinese learners looking to build real fluency by recognizing patterns in the structure of Chinese characters.

back after a bit of a break. here’s how i’m phasing the MVP development:
MVP has two flows:
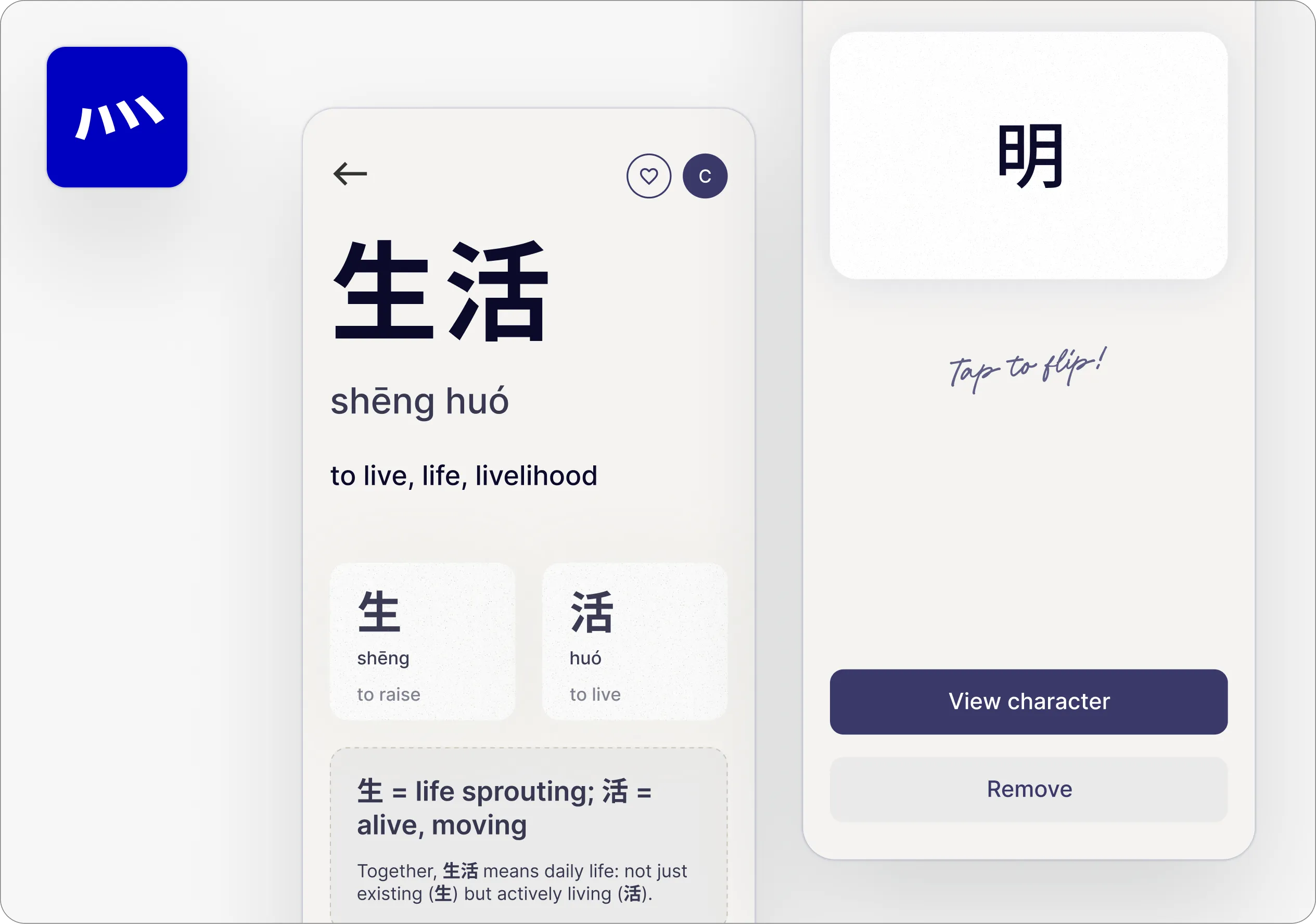
There are 5 “levels” of entities that need different treatment.
Each level needs a different design treatment. L1 shows word-level breakdown, L2 shows character components, and L3–L5 show etymology and usage.
I started with the idea of building my own dataset, but it seemed high friction and not very sustainable. Building a comprehensive, accurate dataset would take a lot of effort.
Landed on a scoped v0. I would curate 500–700 characters, Simplified Chinese only, 1-2 core user flows, and see how it goes
I also decided on web app over iOS for now to have the lowest possible barrier to iterating / shipping without dealing with app store reviews.
Realised that instead of curating a static dataset, I could use AI for the character breakdowns. This shifts the entire approach. I can support the full character set from day one and ship much faster.
My thinking on ICP has shifted. Heritage learners were my initial focus, but the opportunity is broader: serious, intermediate learners frustrated with retention and comprehension. The pain point is universal.
I looked at the competitive landscape more closely and did some product teardowns:
I should consider adding stroke order, and spaced repetition flashcards for feature parity, but it’s not critical for v0 Considered going mobile again because demand validation is much stronger now, but chose to stick with web to ship faster